RTC
Real-time Chunking (RTC) 解决的是一个非常具体的问题,即当推理速度赶不上执行速度的时候,如何避免 action chunk 之间的停顿,使整体动作变平滑。
真机每隔固定 $\Delta t$ 消费一个 action,服务器(模型)每次推理生成一个长度为 $H$ 的 action chunk,从获得 observation 到得到 action 的延迟估计为 $d \Delta t$(先假设是固定的)。如果每次消费完一个 action chunk 之后才开始新的推理,就会像下面这样两个 chunk 中间有 $d$ 个时间步的停顿。
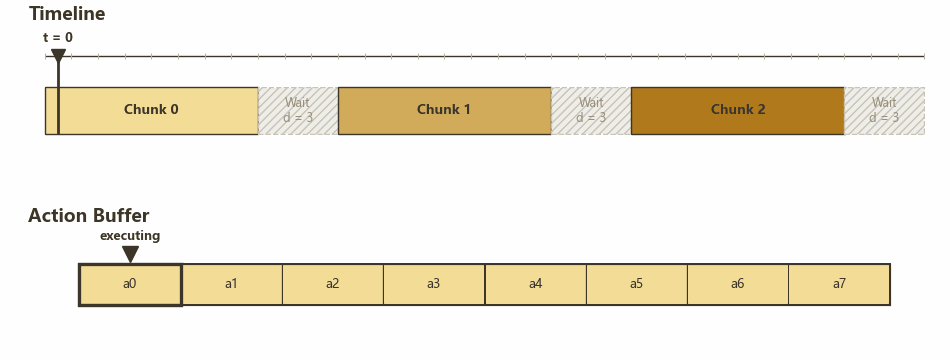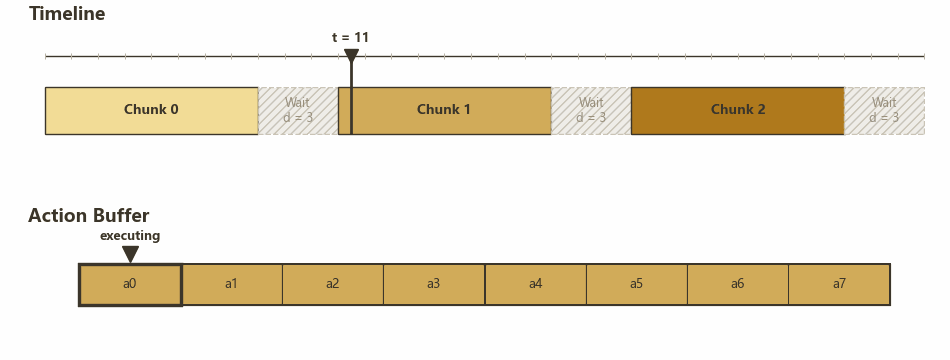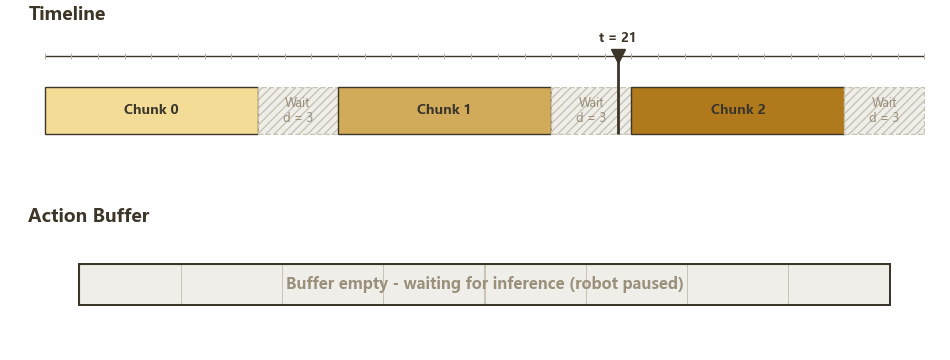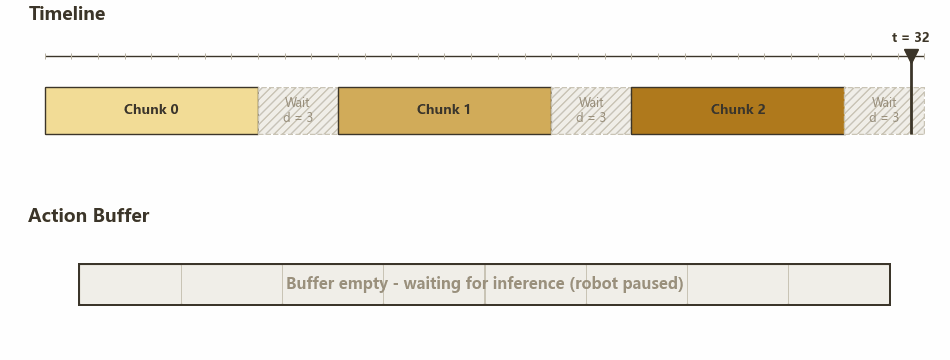
No RTC
当 $d < H$ 时,自然可以想到可以在上一个 chunk 还没消费完时,就启动下一个 chunk 的推理,这样两个 chunk 就能无缝衔接。这样的过程称为异步推理,与上面的同步推理对应。
由于 chunk 拿到 observation 和开始执行之间存在 $d$ 个时间步的延迟,因此每个 chunk 的前 $d$ 个 action 是没用的。引入一个超参数 $s$ 表示不同 action chunk 的重叠程度,即当前 action buffer 执行到第 $s$ 个 action 的时候开始新的推理,等价于新的 action chunk 超出前一个 chunk $s$ 个时间步,提供 $s$ 个全新的 action。
- 在极端情况下,我们可以另 $s=1$,此时 chunk 之间的重合度最高,但意义不大,相当于每个 chunk 只额外提供 1 个新的 action,所以 $s$ 不能太小。
- $s$ 不应该超过 $H-d$,否则 chunk 之间就会出现间隔。
- 合理的 $s$ 范围是 $d \leq s \leq H - d$。当 $d > H/2$ 时这个条件无法严格满足,原文的选择是始终保证 $s \geq d$,有波动造成 $d$ 过大时就接受卡顿。
下图展示了 RTC 的 chunk 切换流程:
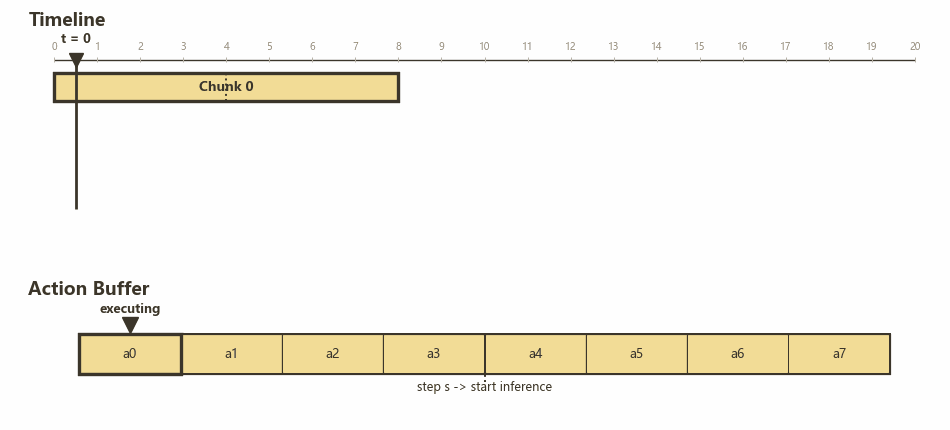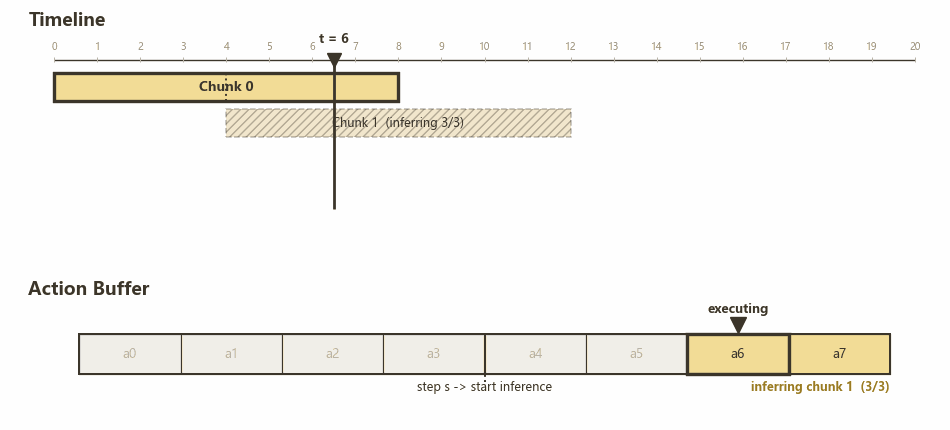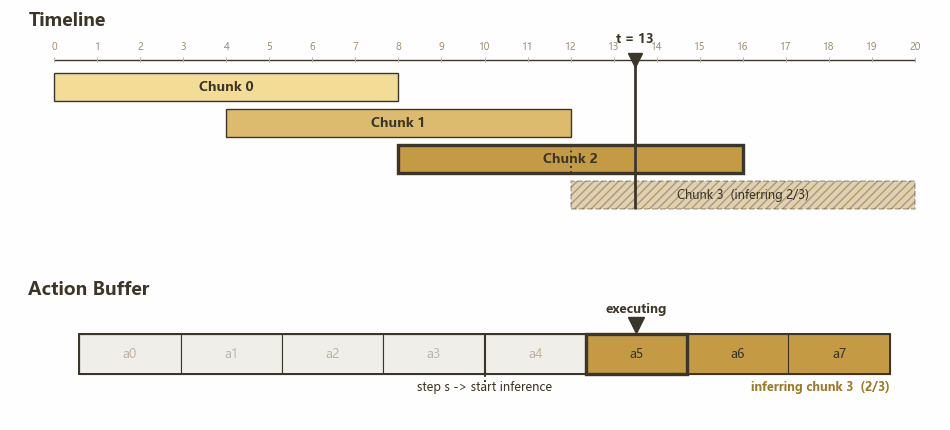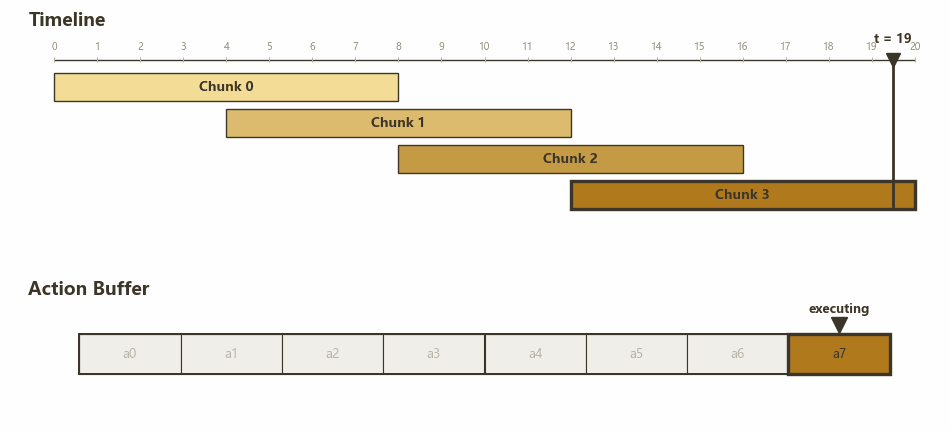
RTC: H=8, s=4, d=3
由于延迟的存在,新的 chunk 基于的是旧的 observation,前 $d$ 个 action 和上一个 chunk 可能不一致,导致 $d$ 之后的 action 跟前面 chunk 的 action 不连续。在下图展示的避障场景中,两个 chunk 选择不同的方向避障,导致动作产生跳变。
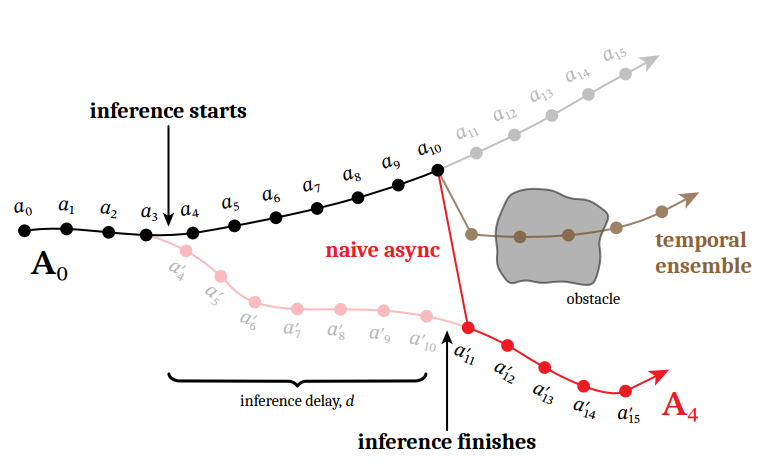
An illustration of a typical bifurcation between consecutive chunks. Paper
为了避免这种情况,我们需要在新 chunk 生成的时候,把老的 chunk 作为 condition,保证生成结果的一致性。每次生成新的 chunk 时,前 $H - s$ 个 action 是已知的,后 $s$ 个是未知的,这就类似于图像生成中的 inpainting 问题。原文直接找了一个图像生成中的解法 $\Pi$GDM。由于是 23 年的文章,所以还是从 SDE 那一套推出来,RTC 里直接给出来了 Flow Matching 的形式,这里简单推一下。
问题的形式是,对于生成的动作 $x$ 我们有部分观测 $y=Wx$,$W$ 是一个 mask。我们希望在 $y$ 的监督下引导 flow 的过程,使得生成的 action 在 mask 内跟已知值 $y$ 一致。原本 flow 的概率轨迹是 $p_t(x_t)$,现在希望遵循 $p_t(x_t|y)$。通过贝叶斯定律有:
$$ \nabla_{x_t} \log p_t(x_t|y) = \nabla_{x_t} \log p_t(y|x_t) + \nabla_{x_t} \log p_t(x_t). $$
$\nabla \log p$ 就是 Score Matching 中的 score,与 Flow Matching 中的 velocity 有一次函数关系, Introduction to Flow Matching and Diffusion Models 2026 因此所有关于 score 的分析都可以直接套用到速度上。在最简化的线性 flow 情况下($\alpha=t, \beta=1-t$),有:
$$ u_t(x_t|y) = u_t(x_t) + \frac{1-t}{t} \nabla_{x_t} \log p_t(y|x_t). $$
在估计最后一项时,$y$ 与 $x_1$ 直接相关,因此核心变成估计 $p(x_1|x_t)$。直接计算需要我们追踪 flow 的过程,开销太大。因此我们使用一个高斯分布进行近似:期望为一步 denoise 的结果 $\hat{x}_1 = x_t + (1 - t) u_t^\theta(x_t)$,方差为 $r_t^2 I$,暂时我们假定为超参数。又根据 $y=Wx$,得到:
$$ p_t(y|x_t) = \mathcal{N}(y; W \hat{x}_1, W W^\top r_t^2 ). $$
带入到上面得到最终速度更新的公式:
$$ u_t(x_t|y) = u_t(x_t) + \frac{1-t}{tr_t^2} (y - W \hat{x}_1)^\top W^\dagger \frac{\partial \hat{x}_1}{\partial x_t}. $$
其中 $W^\dagger = (WW^\top)^{-1}W$ 是 $W$ 的伪逆,对于 mask 而言,就是 W 本身。最后一项的偏导数可以通过网络自动微分得到。
$r_t$ 在上面的过程中主要起到缩放的作用,因此估计一个差不多的值就可以。首先有 $p(x_t|x_1)=\mathcal{N}(x_t; tx_1, (1-t)^2 I)$,在最简化的情况下可以假定 $p(x_1) = \mathcal{N}(x_1; 0, I)$,于是根据 $p(x_1|x_t) \propto p(x_t|x_1) p(x_1)$ 得到 $p(x_1|x_t)$ 的方差为:
$$ r_t^2 = \frac{(1-t)^2}{(1-t)^2 + t^2}. $$
此外,为了进一步增加稳定性,最终原文还限制了系数最小不能小于 $\beta$。
而对于 mask $W$,原文使用了一个 soft mask 的形式。每个 chunk 的前 $d$ 个 action 应该直接使用 $W_i = 1$,表示完全跟之前的 action 相同。在 $d$ 到 $H - s$ 之间的 action 与之前的 chunk 重叠,应该平滑从 1 过渡到 0。而在 $H - s$ 之后的 action 之前的 chunk 没有,应该让 $W_i = 0$ 表示完全自由生成。
Traing-time RTC
RTC 在推理时还需要通过自动微分来计算导数,增加了额外的计算开销,因此最好是让网络本身就有给定 action 条件生成的能力,这就自然对应 training-time RTC 的想法。其核心的改动就是对应下面的架构图:
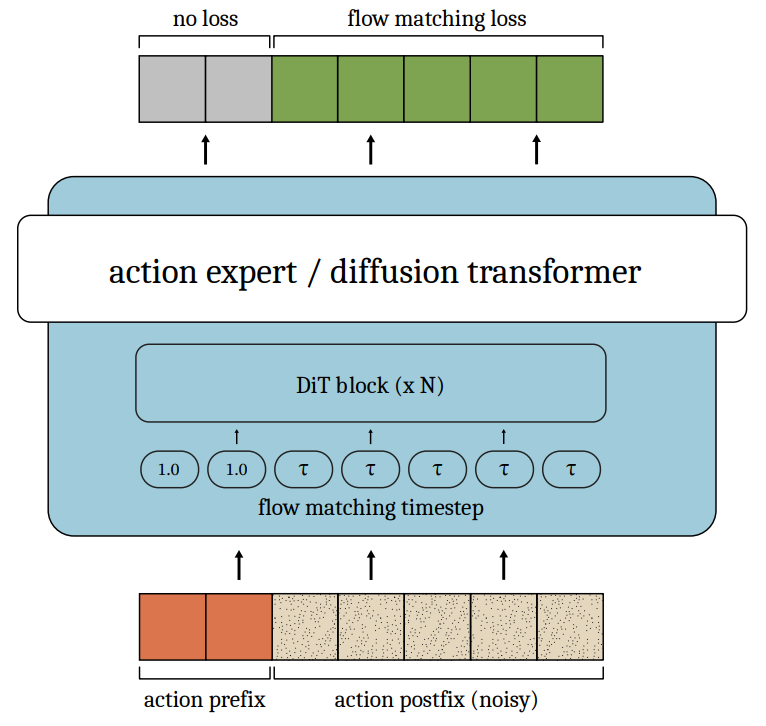
Action conditioning architecture. Paper
Prefix 的 action 给定真值和 $t=1$,其他部分正常 denoise,计算 loss 的时候只算 postfix 的部分。Prefix 的长度在训练时随机选择。
总结
RTC 的想法不难理解,基本都是工程实践,但是效果非常好。究其本质,如果推理的速度足够快,也就不需要这些 trick 了,这方面优化得最好的是 Real-time VLA 系列。Traing-time RTC 单看 action 其实就是 Teacher Forcing,如果想要更快的推理速度,完全可以使用 Diffusion Forcing/Self Forcing 类似的思路,基于之前带 denoise 的历史,直接生成新的动作。理想情况下,动作生成应该是类似滑动窗口一样连续不断的过程。